🔎 Why Does It Take So Much Time To Retrieve Information About The Same Folder?
What if folder properties, verification, recovery, and observability no longer required repeated rediscovery at query time?
📂 Imagine opening a folder containing fifty thousand files.
You ask:
How large is it?
How many files exist?
Can I verify it?
Can I recover it?
Did something change?
How long will this take?
Modern systems often behave as though answering these questions requires something familiar:
scan again
count again
traverse again
rediscover again
We rarely question this.
The folder already exists.
The files already exist.
The structure already exists.
Yet retrieval often begins with rediscovery.
As folders grow larger, verification grows, recovery grows, observability grows, and repeated rediscovery quietly becomes part of normal operation.
Much of modern engineering therefore focuses on making repeated rediscovery faster rather than questioning whether repeated rediscovery itself is fundamentally necessary.
Representative demonstrations produced something worth examining.
Approximately 50,000 files produced:
structural lookup ~5 us
recursive traversal ~50,000 ms
The question therefore becomes:
Must folder properties, verification, recovery, and observability fundamentally require repeated rediscovery at query time?
Or can maintained current structure preserve observable truth instead?
STRUE — Structural Truth Engine — explores this question.
🏗 STRUE Architecture — Preserving Observable Truth Through Maintained Current Structure
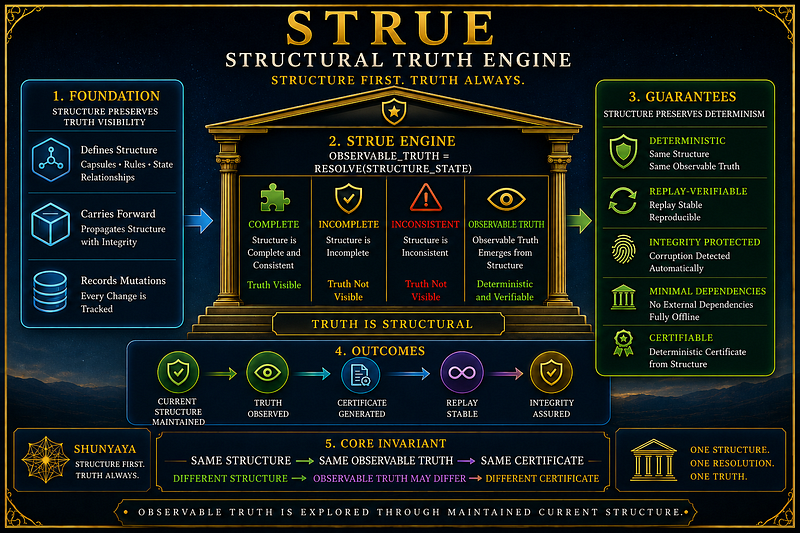
Maintained current structure enables observable truth, verification, recovery, and deterministic retrieval within the modeled boundary.
🚫 What STRUE Is Not
Before going further:
STRUE does not attempt to replace filesystems, storage systems, databases, object stores, operating systems, or existing infrastructure.
It explores something narrower:
a structural truth and observability layer that sits alongside existing systems.
The question is not:
“How do we make traversal faster?”
The question becomes:
“Must query-time retrieval fundamentally require repeated rediscovery when maintained current structure already preserves truth?”
⚖️ How STRUE Differs From Existing Approaches
+--------------------------------+---------------------------------------------------------------+-------------------------------------------------------------+
| Approach | How properties are retrieved | STRUE difference |
+--------------------------------+---------------------------------------------------------------+-------------------------------------------------------------+
| Recursive traversal systems | Properties computed through repeated traversal during query | Reads maintained capsules instead |
| Event-driven change systems | Changes detected incrementally but retrieval may still | Propagates structural aggregates during mutation |
| | require additional aggregation | |
| Content-addressed structures | Preserve identity and structure rather than aggregate | Maintains size, file_count, and dir_count structurally |
| | property retrieval | |
| External metadata systems | Metadata maintained through additional infrastructure | Uses lightweight maintained structural state |
+--------------------------------+---------------------------------------------------------------+-------------------------------------------------------------+The core distinction:
Traditional approaches often reconstruct properties during retrieval.
STRUE explores:
mutation -> propagation -> maintained_structure -> retrieval
rather than:
retrieval -> traversal -> reconstruction
Traditional approaches often assume a familiar progression:
folder -> traversal -> properties -> observable_truth
This approach is not necessarily wrong.
Traversal remains important.
Initialization may require traversal.
Synchronization may require traversal.
Verification may require traversal.
Recovery may require traversal.
STRUE explores a narrower question.
If maintained current structure already preserves observable truth, must query-time retrieval fundamentally require repeated rediscovery?
The central invariant explored by STRUE becomes:
truth_visible iff structure_updatedwhere:
observable_truth = resolve(structure_state)This creates a different structural question.
Instead of asking:
“How quickly can we repeatedly rediscover observable truth?”
The question becomes:
“Can observable truth remain structurally visible before query-time rediscovery begins?”
This is not traversal removal.
This is structural truth exploration.
⚡ The 90-Second Structural Proof
The easiest way to evaluate STRUE is not through theory.
It is through execution.
Python 3.9+ required.
No external dependencies.
stdlib only.
Clone the repository:
git clone https://github.com/OMPSHUNYAYA/STRUE.gitcd STRUE
Create a demonstration:
python demo/STRUE_v1_2.py demo --root STRUE_DEMO --files 1000 --cleanCheck structural state:
python demo/STRUE_v1_2.py status --root STRUE_DEMOVerify structural truth:
python demo/STRUE_v1_2.py verify --root STRUE_DEMOObserve benchmark behavior:
python demo/STRUE_v1_2.py benchmark --root STRUE_DEMO --path ProjectExpected observations:
- folder properties become structurally visible
- deterministic certificates remain stable
- corruption becomes observable
- recovery becomes inspectable
- replay remains deterministic
- identical structure preserves identical truth
The objective is intentionally simple:
Inspect it.
Replay it.
Modify it.
Break it.
These are not static architecture diagrams.
These are executable structural demonstrations.
🧩 Structural Capsules — Preserving Observable Truth
STRUE preserves structural truth through bounded structural containers called capsules.
Capsules preserve information such as:
- folder size
- file count
- directory count
- mutation information
- structural certificates
- truth certificates
- structural metadata
A capsule is a lightweight structural container represented in the current reference implementation as JSON.
A simplified example looks like this:
{
"path": "Project",
"state": "RESOLVED",
"size_bytes": 63963,
"file_count": 1001,
"dir_count": 4,
"mutation_id": 1,
"certificate": "a3b802e87a3e37...",
"truth_source": "maintained_structure",
"traversal_used_for_property_lookup": false
}Under this direction, retrieval explores:
read(capsule)
rather than repeatedly requiring:
recursive_discovery(folder)
during query-time retrieval.
The consequence becomes important.
Instead of repeatedly reconstructing observable truth during retrieval, structural truth is propagated during mutation and preserved within maintained current structure.
This creates a different structural relationship:
mutation -> propagation -> maintained_structure -> retrieval
rather than:
retrieval -> traversal -> reconstruction
This does not imply traversal disappears.
It explores something narrower.
Can observable truth remain structurally visible before traversal-based rediscovery begins?
This question ultimately produces the deterministic invariant repeatedly explored throughout STRUE:
same_structure -> same_truth -> same_certificates
📊 Representative demonstrations produced something worth examining carefully.
+--------+--------------------------------+-------------+
| Files | Structural Lookup (preloaded) | Traversal |
+--------+--------------------------------+-------------+
| 1,000 | ~3 us | ~1,300 ms |
| 10,000 | ~4 us | ~13,000 ms |
| 50,000 | ~5 us | ~50,000 ms |
+--------+--------------------------------+-------------+Two distinct cost models are reported and should be interpreted separately.
Preloaded lookup speedup
The cost of a single property read against an already-loaded index.
Approximately ~3-5 us.
This represents structural retrieval cost once maintained current structure is already resident in memory.
End-to-end query speedup
The cost of:
index_load + lookup
Approximately ~8-480 ms depending upon demonstrated scale.
This represents a cold-query scenario and is reported separately as:
structure_query_total_ms
Both measurements are descriptive observations from the reference environment.
Neither measurement is a universal guarantee.
Raw benchmark outputs are available in:
VERIFY/benchmark_raw_results.txt
The important observation is not the absolute numbers.
The important observation is the behavior.
Structural lookup remained approximately flat as demonstrated folder sizes increased.
Traversal cost increased with object count.
The structural direction explored by STRUE becomes:
retrieval_cost proportional_to mutation_set
rather than:
retrieval_cost proportional_to object_count
within maintained current structure.
The structural question therefore becomes:
If maintained current structure already preserves observable truth,
what fundamentally determines retrieval cost?
🛡 Verification, Recovery, and Structural Observability
Observable truth becomes more interesting when something goes wrong.
Folders mutate.
Files change.
Structures drift.
Corruption appears.
Recovery becomes necessary.
STRUE therefore treats observable truth as something that should remain inspectable.
Verification compares expected structural truth against observed structural truth.
Inject corruption:
python demo/STRUE_v1_2.py corrupt --root STRUE_DEMO --path Project --mode size --delta 9Verify:
python demo/STRUE_v1_2.py verify --root STRUE_DEMORecover:
python demo/STRUE_v1_2.py recover --root STRUE_DEMOThe expected structural behavior becomes:
corruption -> verification_failure
preserved_structure -> recovery -> observable_truth
STRUE repeatedly explores the invariant:
same_structure -> same_truth
same_structure -> same_certificates
same_structure -> same_observability
The objective is intentionally simple.
Truth should remain inspectable.
Corruption should become observable.
Recovery should become reproducible.
Replay should remain deterministic.
These properties become easier to inspect when truth itself becomes structural rather than repeatedly reconstructed during retrieval.
🧪 Interactive Structural Observatory
STRUE includes an offline browser observatory for inspecting structural truth directly.
The objective is simple:
Structural observability should itself be observable.
Start a local server:
python -m http.server 8000 --directory demoOpen:
http://localhost:8000/STRUE-Explorer-v1_2.htmlThe observatory allows structural truth to become inspectable through:
- structural property visualization
- mutation propagation
- corruption injection
- recovery validation
- replay verification
- benchmark inspection
- deterministic observability testing
The browser observatory intentionally behaves like an interactive structural laboratory rather than a static dashboard.
Example browser commands:
STRUE.show()
STRUE.batch(100)
STRUE.verify()
STRUE.corrupt()
STRUE.recover()
STRUE.smoke()
The objective remains intentionally simple:
Inspect structure.
Inject failures.
Observe recovery.
Replay truth.
Challenge invariants.
These are not static architecture diagrams.
These are live structural demonstrations.
🔍 The Challenge — Inspect The Invariants
STRUE intentionally invites falsification.
Clone the repository and attempt to demonstrate any of the following within the reference implementation:
- identical structure produces different truth
- replay produces different certificates
- corruption remains invisible to verification
- recovery reconstructs incorrect observable truth
- query-time retrieval fundamentally requires repeated rediscovery despite maintained current structure
If any of these can be demonstrated:
the structural model fails within that demonstrated space.
That result is worth knowing.
That result improves the model.
If none can be demonstrated:
maintained current structure may preserve observable truth within the modeled structural space.
The objective is not agreement.
The objective is reproducible inspection.
Run verification:
python demo/STRUE_v1_2.py verify --root STRUE_DEMORun replay:
python demo/STRUE_v1_2.py replay --root STRUE_DEMORun recovery:
python demo/STRUE_v1_2.py recover --root STRUE_DEMOObserve:
same_structure -> same_truth
same_structure -> same_certificates
same_structure -> same_observability
The objective remains intentionally simple:
Inspect it.
Replay it.
Modify it.
Challenge it.
These demonstrations are intentionally small.
Not because the problem is small.
Because small demonstrations isolate invariants.
🌍 Where This Direction Matters
The demonstrations are intentionally small.
The implications are not.
Folder properties are only one example.
The broader structural question becomes:
Can observable truth remain structurally visible without repeatedly rediscovering it during retrieval?
This question may become relevant anywhere hierarchical structures continuously accumulate observable properties.
🏭 One concrete direction worth examining: build systems and artifact caching systems.
Many build systems periodically compute cache sizes, artifact counts, storage consumption, and dependency statistics across large directory hierarchies.
These operations frequently rely upon repeated enumeration.
As artifact trees grow — particularly within large repositories containing thousands of build targets — these enumeration costs may accumulate across cache checks, invalidation decisions, storage accounting, and observability queries.
A STRUE-style capsule layer instead maintains these aggregates structurally during mutation.
When artifacts change:
size changes propagate
count changes propagate
structural truth propagates
When a downstream system asks:
“How large is this cache partition?”
retrieval explores:
read(capsule)
rather than:
recursive_discovery(partition)
The structural question therefore shifts from:
“When should we re-scan?”
toward:
“How should structural truth propagate during mutation?”
This direction does not replace build systems.
It explores whether storage accounting and cache observability may remain structurally visible without repeated rediscovery.
Other directions where similar questions may become relevant:
- observability and monitoring systems
- cloud object metadata aggregation
- package registry indexes
- artifact repositories
- hierarchical metric systems
- storage accounting systems
- infrastructure verification systems
Important open questions remain:
- concurrent writers
- distributed propagation
- partial synchronization
- structural consistency across failure boundaries
- large-scale deployment behavior
- mutation contention and propagation cost
The objective is not universal applicability.
The objective is exploring whether maintained current structure can preserve observable truth within bounded structural spaces.
📐 The Formal Core
STRUE explores a narrower structural question:
Can observable truth remain structurally visible before traversal-based rediscovery begins?
The central invariant becomes:
truth_visible iff structure_updatedwhere:
observable_truth = resolve(structure_state)Traditional assumptions often resemble:
folder -> traversal -> properties -> observable_truth
STRUE explores:
maintained_current_structure -> observable_truth -> query_time_retrieval
The deterministic invariant repeatedly explored throughout STRUE becomes:
same_structure -> same_truth
same_structure -> same_certificates
same_structure -> same_observability
This also creates a different retrieval relationship.
Instead of:
retrieval_cost proportional_to object_count
STRUE explores:
retrieval_cost proportional_to mutation_set
within maintained current structure.
This does not imply:
- traversal disappears
- filesystems disappear
- storage disappears
- infrastructure disappears
The structural question explored is narrower:
If maintained current structure already preserves observable truth, what fundamentally determines query-time retrieval?
This is ultimately why STRUE repeatedly explores structural truth as something preserved rather than repeatedly reconstructed.
📋 Scope and Boundaries
STRUE is intentionally explored through bounded reference demonstrations.
It does not claim:
- filesystem replacement
- storage replacement
- operating system replacement
- universal performance guarantees
- infrastructure replacement
- universal traversal elimination
- production deployment guarantees
Traversal still exists within STRUE.
Traversal may still participate in:
- initialization
- synchronization
- verification
- recovery
- release validation
The narrower claim explored by STRUE is:
maintained_current_structure -> observable_truth -> query_time_retrieval
rather than:
retrieval -> traversal -> reconstruction
One important boundary condition should be understood explicitly.
Maintained current structure reflects truth only when mutations occur within the modeled mutation boundary.
Changes made through external processes, operating system actions, or tools outside STRUE require explicit synchronization before structural truth becomes current again.
The benchmark output states this directly:
staleness_model=explicit_sync_required_for_out_of_band_changes
This is not a failure condition.
It is the explicit scope of the reference model.
Maintained current structure preserves truth within the modeled mutation boundary.
Outside that boundary:
synchronization -> maintained_current_structure -> observable_truth
Synchronization may require traversal.
Traversal therefore remains an appropriate tool for synchronization, initialization, verification, recovery, and other boundary operations.
The demonstrations therefore explore whether:
- query-time property retrieval may not fundamentally require repeated rediscovery within the modeled mutation boundary
- corruption becomes structurally observable
- recovery reconstructs observable truth from preserved structural state
- identical structure preserves identical truth and certificates
- structural observability remains deterministic and replayable
The demonstrations remain intentionally small.
Not because the structural question is small.
Because smaller demonstrations isolate invariants more clearly.
STRUE therefore should be viewed as:
structural truth exploration
rather than:
infrastructure replacement
🌐 STRUE Within the Broader Structural Direction
STRUE is one demonstration inside a much larger structural direction.
The broader Dependency Elimination Framework explores a single converging question across domains:
Were the dependencies we assumed fundamental ever truly fundamental?
The core law explored across these domains becomes:
outcome_visible iff structure_complete AND structure_consistentTraversal is one dependency domain explored within this framework — alongside time, ordering, execution, connectivity, computation, cloud infrastructure, identity, consensus, and others.
Each domain explores the same question:
If a dependency is removed,
does the desired outcome remain preserved?
If it does,
the dependency may not have been fundamental.
STRUE applies this question specifically to observable truth and query-time retrieval.
Observable truth may remain preserved while retrieval becomes structurally governed.
Across 75+ structural systems spanning correctness, time independence, network independence, observability, communication, infrastructure, identity, traversal, and dependency-heavy domains, the broader Shunyaya ecosystem has repeatedly explored this same structural direction.
Each system remains independently demonstrable and falsifiable while exploring the same principle:
Remove what was never fundamental.
Preserve structure.
Observe what remains.
The easiest way to evaluate this direction is not through assertion.
It is through inspection.
Explore the broader ecosystem on GitHub:
Shunyaya Master Repository
The challenge remains open.
Clone the repository.
Attempt to falsify the invariants.
Observe what remains.
same_structure -> same_truth -> same_certificates
Structure first. Truth always.
OMP


Comments
Post a Comment